Introduction
Tractibility concerns become evident when considering likelihood estimation for a Variational Autoencoder. Unable to maximize the marginal distribution pθ(x)=∫pθ(x|z)pθ(z)dz due to complexity of integrating over the high dimensional latent space $z$, it is also prohibitive to maximize the bayesian representation $p_\theta(x) = p_\theta(x|z)p_\theta(z)/p_\theta(z|x)$ because of the posterior $p_\theta(z|x)$. To circumvent this tractibility concern an auxiliary network, $q_\phi(z|x)$, is introduced to approximate the posterior: $q_\phi(z|x) \approx p_\theta(z|x)$.
The relationship between the auxiliary network, popularly referred to as the encoder, and the posterior distribution will provide a tractible means for likelihood estimation and is what will become known as the variational lower bound or the evidence lower bound (ELBO). Then by jointly updating parameters $\phi$ and $\theta$ via some gradient optimization (maximizing likelihood), the Variational Autoencoder increases in efficacy.
The goal here is to "homogenize" the information I've found on VAEs. Different sources on the network begin explanation differently, so some people (me) are prone to confusion. By sewing together these sources, the different philosophies are packaged together and presented, hopefully, with a bow on top.
Variational Lower Bound (or ELBO)
The variational lower bound, $\mathcal{L}$, is a value that is always less than or equal to the proposed density $\log{p_\theta(x)}$. By maximizing the tractible $\mathcal{L}$, the intractible marginal likelihood, $p_\theta(x)$, is also maximized. Note that applying the monotonic transformation $\log{f(x)}$ to some function $f(x)$ preserves local extrema which does not conflict with maximum likelihood estimation. Below are three different ways to arrive at $\mathcal{L}$.
Starting with: log p(x)
$$\begin{align}
\log{p_\theta(x)} & = \mathbb{E}_{q_{\phi}(z|x)}[\log{p_\theta(x)}] && \mathbb{E}_p[C] = C, \text{where C is constant to distribution p} \tag{1.0} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(x, z)}{p_\theta(z|x)}}\biggr] && \text{probability chain rule}\tag{1.1} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(x, z)q_\phi(z|x)}{q_\phi(z|x)p_\theta(z|x)}}\biggr] && \text{multiply by "1"}\tag{1.2} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(x, z)}{q_\phi(z|x)}\biggr] + \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{q_\phi(z|x)}{p_\theta(z|x)}}}\biggr] && \text{segregate}\tag{1.3} \\[2ex]
& = \mathcal{L} + D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z|x)) \tag{1.4} \\[2ex]
\log{p_\theta(x)} & \geq \mathcal{L} \tag{1.5}
\end{align}$$
This is, from what I've seen, the most popular way to formulate $\mathcal{L}$. Equation 1.4 shows the relationship between the marginal likelihood, $\log{p_\theta(x)}$, and $\mathcal{L}$ where the difference between the two values is the KL divergence from the encoder, $q_\phi(z|x)$, to the posterior, $p_\theta(z|x)$. Because the KL divergence is non negative, by subtracting it from the RHS we ensure $\log{p_\theta(x) \geq \mathcal{L}}$.
Starting with: Bayes Rule
$\begin{align}
\log{\frac{p_\theta(x|z)p_\theta(z)}{p_\theta(z|x)}} & = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(x|z)p_\theta(z)}{p_\theta(z|x)}}\biggr] && \text{Reasoning from (1.0)} \tag{2.0} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(x|z)q_\phi(z|x)p_\theta(z)}{p_\theta(z|x)q_\phi(z|x)}}\biggr] && \text{multiply by "1"} \tag{2.1} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{p_\theta(x|z)} - \log{\frac{q_\phi(z|x)}{p_\theta(z)}} + \log{\frac{q_\phi(z|x)}{p_\theta(z|x)}}\biggr] && \text{segregate}\tag{2.2} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x|z)} \bigr] - \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{q_\phi(z|x)}{p_\theta(z)}} \biggr] +
\mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{q_\phi(z|x)}{p_\theta(z|x)}} \biggr] \tag{2.3} && \text{distibute expectation} \\[2ex]
& = \underbrace{\mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x|z)} \bigr] - D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z))}_{\text{Variational Lower Bound, }\mathcal{L}} + D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z|x)) && \text{*check below}\tag{2.31} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x|z)} \bigr] + \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(z)}{q_\phi(z|x)}} \biggr] +
D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z|x)) && \text{log reciprocal & definition of KL divergence} \tag{2.4} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(x|z)p_\theta(z)}{q_\phi(z|x)}} \biggr] + D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z|x)) && \text{log product rule} \tag{2.5} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(x, z)}{q_\phi(z|x)}} \biggr] + D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z|x)) && \text{probability chain rule} \tag{2.6} \\[2ex]
& = \mathcal{L} + D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z|x)) \tag{2.7} \\[2ex]
\end{align}$
This explanation is unnecessarily long because it should seem apparent how to get from eq 2.2 to eq 2.7 with understanding of eq 1.0 - 1.5. However eq 2.31 shows a further, very popular, representation of the variational lower bound, also referenced later on: $\mathcal{L} = \mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x|z)} \bigr] - D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z))$. The left term is the reconstruction error or expected reconstruction error and the right is the KL divergence from the encoder to the prior distribution. An alternative formulation is: $\mathcal{L} = \mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x, z)} - \log{q_\phi(z|x)}\bigr]$.
Starting with: KL divergence
$$\begin{align}
D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z|x)) & = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{q_{\phi}(z|x)}{p_\theta(z|x)}} \biggr] && \text{definition of kl divergence} \tag{3.0} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{q_{\phi}(z|x)p_\theta(x)}{p_\theta(z,x)}} \biggr] && p(z|x) = \frac{p(z, x)}{p(x)}\, \text{and reciprocal} \tag{3.1} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{q_{\phi}(z|x)}{p_\theta(z,x)}} + \log{p_\theta(x)} \biggr] && \text{segregate} \tag{3.2} \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{q_{\phi}(z|x)}{p_\theta(z,x)}}\biggr] + \mathbb{E}_{q_{\phi}(z|x)}[\log{p_\theta(x)}] && \text{distribute expectation} \tag{3.3} \\[2ex]
& = -\mathbb{E}_{q_{\phi}(z|x)}\biggl[\log{\frac{p_\theta(z,x)}{q_{\phi}(z|x)}}\biggr] + \log{p_\theta(x)} && \text{log reciprocal and reasoning from (1.0) & (2.0)} \tag{3.4} \\[2ex]
& = - \mathcal{L} + \log{p_\theta(x)} \tag{3.5} \\[2ex]
\end{align}$$Closed Form Computation of KL Divergence in the ELBO
This section is more of an aside to show the breakdown of the KL divergence term in $\mathcal{L}$ when the prior and encoder are initialized to certain densities. To make sure our ducks are in a row:
- Duck 1: For reference, the lower variational bound referenced in eq 2.31 is: $$\mathcal{L} = \mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x|z)} \bigr] - D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z))$$
- Duck 2: The KL divergence between two multivariate gaussians simplifies to (shown here): $$D_{\mathbb{KL}}(q\,||\,p) \triangleq \frac{1}{2}\Biggl(\log\Bigl(\frac{\det{(\Sigma_2)}}{\det{(\Sigma_1)}}\Bigr) - n +
\text{tr}\bigl(\Sigma^{-1}_2\Sigma_1\bigr)+\bigl(\mu_2-\mu_1\bigr)^\top\Sigma^{-1}_2\bigl(\mu_2-\mu_1\bigr)\Biggr)$$
When both the encoder $q_\phi(z|x)$ and prior $p_\theta(z)$ are multivariate diagonal gaussians, where $q_\phi(z|x) = \mathcal{N}(\mu_1, \Sigma_1) = \mathcal{N}(\mu, \Sigma)$ and $p_\theta(z) = \mathcal{N}(\mu_2, \Sigma_2) =\mathcal{N}(0, I)$, the KL divergence term in $\mathcal{L}$ can be computed. \begin{align}
D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z)) & = \frac{1}{2}\Biggl(\log\Bigl(\frac{|I|}{|\Sigma|}\Bigr) - n +
\text{tr}\bigl(I^{-1}\Sigma\bigr)+\bigl(0-\mu\bigr)^\top I^{-1}\bigl(0-\mu\bigr)\Biggr) && \text{definition. Change det(x) to |x| for readability} \tag{4.0} \\[2ex]
& = \frac{1}{2}\Biggl(\log{|I|} - \log{|\Sigma|} - n + \text{tr}\bigl(\Sigma\bigr)+\mu^\top\mu\Biggr)
&& \text{log quotient property}, I=I^{-1}, IA = A, -1\times -1 = 1\times 1 \tag{4.1} \\[2ex]
& = \frac{1}{2}\Biggl(0 - \log{\prod_i{\sigma_i^2}} - n + \text{tr}\bigl(\Sigma\bigr)+\mu^\top\mu\Biggr)
&& |I| = 1, ln(1) = 0, \text{det of diag matrix = product of diag values} \tag{4.2} \\[2ex]
& = \frac{1}{2}\Biggl(-\sum_i{\log{\sigma_i^2}} - n + \sum_i{\sigma_i^2}+\sum_i{\mu_i^2}\Biggr)
&& \text{convert to sums. Recall diagonal of covariance mat is }\sigma^2 \tag{4.3} \\[2ex]
& = \frac{1}{2}\Biggl(-\sum_i{\bigl(\log{\sigma_i^2}} + 1\bigr) + \sum_i{\sigma_i^2}+\sum_i{\mu_i^2}\Biggr)
&& \text{n = dimension of latent space} \tag{4.4} \\[2ex]
& = \frac{1}{2}\sum_i\Biggl(-\bigl(\log{\sigma_i^2} + 1\bigr) + \sigma_i^2 +\mu_i^2\Biggr)
&& \text{simplify} \tag{4.5}
\end{align}
Gradient Flow
Monte Carlo estimates are used to show the gradients wrt $\theta$ and $\phi$ for the variational lower bound $\mathcal{L}$. In the case of $\nabla_\theta$ and using $\mathcal{L} = \mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x, z)} - \log{q_\phi(z|x)}\bigr]$, the gradient will be:
$$\begin{align}
\nabla_\theta \mathcal{L} & = \nabla_\theta\mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x, z)} - \log{q_\phi(z|x)}\bigr] \\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\bigl[\nabla_\theta(\log{p_\theta(x, z)} - \log{q_\phi(z|x))}\bigr] \\[2ex]
& \approx \nabla_\theta(\log{p_\theta(x, z)} - \log{q_\phi(z|x)}) \quad \text{Monte Carlo estimate where } z \sim q_\phi(z|x) \\[2ex]
& = \nabla_\theta(\log{p_\theta(x, z))} \\[2ex]
\end{align}$$
For $\nabla_\phi$ the process is a little more convoluted because we're seeking the gradient for the parameters of the expectation.
$$\begin{align}
\nabla_\phi \mathcal{L} & = \nabla_\phi\mathbb{E}_{q_{\phi}(z|x)}\bigl[\log{p_\theta(x, z)} - \log{q_\phi(z|x)}\bigr] && \text{definition of } \mathcal{L}\tag{5.0} \\[2ex]
& = \nabla_\phi \int (\log{p_\theta(x, z)} - \log{q_\phi(z|x)})q_{\phi}(z|x)dz && \text{continuous latent space z} \tag{5.1}\\[2ex]
& = \nabla_\phi \int \log{p_\theta(x, z)}q_{\phi}(z|x)dz - \nabla_\phi \int \log{q_\phi(z|x)}q_{\phi}(z|x)dz && \text{distribute terms} \tag{5.2}\\[2ex]
& = \int \log{p_\theta(x, z)}\nabla_\phi q_{\phi}(z|x)dz - \int \bigl(\log{q_\phi(z|x)} \nabla_\phi q_{\phi}(z|x) + \nabla_\phi q_{\phi}(z|x)\bigr)dz && \text{product rule on RHS} \tag{5.3}\\[2ex]
& = \int \log{p_\theta(x, z)}\nabla_\phi q_{\phi}(z|x)dz - \int \log{q_\phi(z|x)} \nabla_\phi q_{\phi}(z|x)dz + \nabla_\phi \int q_{\phi}(z|x)dz && \text{distribute integral on RHS} \tag{5.4}\\[2ex]
& = \int \log{p_\theta(x, z)}\nabla_\phi q_{\phi}(z|x)dz - \int \log{q_\phi(z|x)} \nabla_\phi q_{\phi}(z|x)dz && \int q_\phi(z|x)dz = 1, \nabla_\phi 1 = 0 \tag{5.5}\\[2ex]
& = \int (\log{p_\theta(x, z)} - \log{q_\phi(z|x)}) \nabla_\phi q_{\phi}(z|x)dz && \text{combine terms & factor out } \nabla_\phi q_\phi(z|x) \tag{5.6}\\[2ex]
& = \int (\log{p_\theta(x, z)} - \log{q_\phi(z|x)}) q_{\phi}(z|x) \nabla_\phi \log{q_{\phi}(z|x)}dz && \text{chain rule, }\frac{d}{dx}\log{(x)} = \frac{1}{x}\log{\biggl(\frac{d}{dx}x\biggr)} \tag{5.7}\\[2ex]
& = \mathbb{E}_{q_{\phi}(z|x)}\bigl[(\log{p_\theta(x, z)} - \log{q_\phi(z|x)}) \nabla_\phi \log{q_{\phi}(z|x)}\bigr] && \text{convert back to expectation} \tag{5.8}\\[2ex]
& \approx (\log{p_\theta(x, z)} - \log{q_\phi(z|x)}) \nabla_\phi \log{q_{\phi}(z|x)} && \text{Monte Carlo estimate where } z \sim q_\phi(z|x) \tag{5.9}\\[2ex]
\end{align}$$
Reparameterization Trick
The reparameterization trick is a procedure that segregates the stochasticity in $z$ from the desired parameters for backpropogation. This provides two benefits. One, reparameterization is a variance reduction technique. Although these estimates can provide tractible means to calculate $\nabla_{\theta,\phi}$, they express high variance making them impractical for use. By reducing variance, we ensure a more appropriate gradient for the model to learn. Two, reparameterization also guarantees the function to be differentiable because $\nabla_\phi q_\phi(z|x)$ is not always possible to compute. By eschewing the gradient's parameters from this density's parameters, we circumvent this issue.
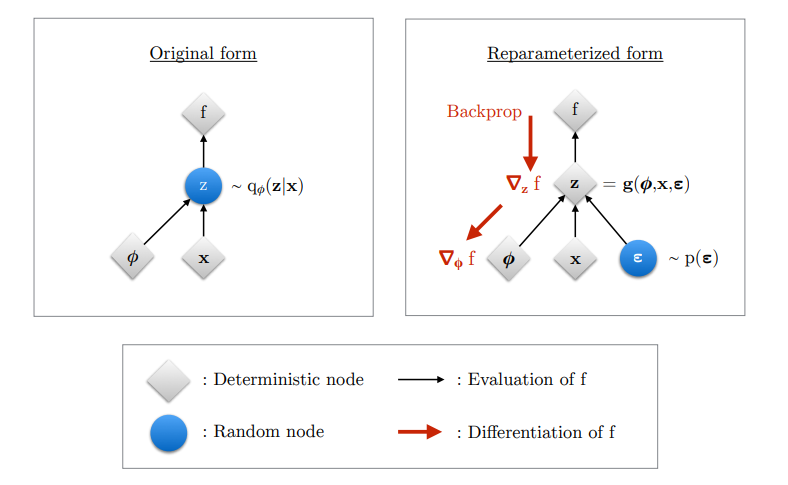
Figure 2.3 from "An Introduction to Variational Autoencoders"
Reparameterization introduces an intermediary function $g$ such that instead of $z \sim q_\phi(z|x)$, $z = g(\phi, x, \epsilon)$ where the stochasticity is delegated to random variable $\epsilon \sim p(\epsilon)$. The desired parameter for backpropagation, $\phi$, now becomes deterministic and provides a more reliable flow downstream. On a more tangible level this converts a lot of the headache witnessed in equations 5.X to something more approachable because, by reparameterizing $z$, the parameters of the density of the expectation changes, which in turn allows the gradient to be inside the expectation.
\begin{align}
\nabla_\phi\mathbb{E}_{q_\phi(z|x)}[f(z)] & = \nabla_\phi\mathbb{E}_{p(\epsilon))}[f(g(\phi, x, \epsilon))] && \text{where } z = g(\phi, x, \epsilon), \epsilon \sim p(\epsilon) \\[2ex]
& = \mathbb{E}_{p(\epsilon))}[\nabla_\phi f(g(\phi, x, \epsilon))] \\[2ex]
& \approx \nabla_\phi f(g(\phi, x, \epsilon)) && \text{Monte Carlo estimate where } \epsilon \sim p(\epsilon)
\end{align}
With reparameterization, the two representations of the variational lower bound $\mathcal{L}$ shown in "Starting with: Bayes Rule" are called the Stochastic Gradient Variational Bayes Estimator (SGVB) and can be represented as:
$$\begin{align}
\mathcal{L} & \approx \mathcal{\widetilde{L}}^A \\
& = \frac{1}{L}\sum_{l=1}^L \log{p_\theta(x, z^l)} - \log{q_\phi(z^l|x)} && \text{where } z^l = g(\phi, x, \epsilon^l) \text{ and } \epsilon^l \sim p(\epsilon) \\
& \text{and} \\[2ex]
\mathcal{L} & \approx \mathcal{\widetilde{L}}^B \\
& = - D_{\mathbb{KL}}(q_\phi(z|x)\,||\,p_\theta(z)) + \frac{1}{L}\sum_{l=1}^L\log{p_\theta(x|z^l)} && \text{where } z^l = g(\phi, x, \epsilon^l) \text{ and } \epsilon^l \sim p(\epsilon) \\
& = \frac{1}{2}\sum_i\Biggl(\log{\sigma_i^2} + 1 - \sigma_i^2 - \mu_i^2\Biggr) + \frac{1}{L}\sum_{l=1}^L\log{p_\theta(x|z^l)} && \text{sub in eq 4.5}
\end{align}$$